Da ich im Juli 2025 in eine Vollanstellung als Technischer Redakteur/Wissensmanager und DeFrEnT nur noch nebenberuflich weiterführe, stellte sich natürlich die betriebswirtschaftliche Frage, ob es sich noch einmal lohnt, hunderte…
Translators’ fees: per standard page, per standard line, per word, per hour?
While per word and per hour fees for translations are known around the world, Germany has two additional invoicing units: per standard line and per standard page. In 2019, I…
How to display RoboHelp XLIFF nicely in Firefox with CSS

This article shows how to style RoboHelp XLIFF files (.xlf) with CSS to nicely display them in Firefox as Type, Source, Segmented Source, Seg. Target, Notes.
Dolmetscher und Übersetzer: Stark im Verband
Ich bin technischer und beeidigter Übersetzer für Französisch und Englisch. Für andere Sprachen oder Fachgebiete empfehle ich mein Netzwerk von BDÜ-Kollegen!
CAT-Tools: Helfer für die Übersetzung
Vor kurzem wurde ich von der KI von LinkedIn eingeladen, mich über technische Helfer zur Beschleunigung des Übersetzungsprozesses auszulassen – in Englisch und mit Zeichenlimit (den kollaborativen LI-Artikel zu CAT-Tools…
Übersetzungsgerechtes Schreiben: Layout und Medien
Wie Datei- und Formatvorlagen und eine gute Vorbereitung von Audio-/Video-Inhalten und Bildern Ihre Inhalte einfacher zu übersetzen macht.
WordPress WPML XLIFF in Trados Studio übersetzen
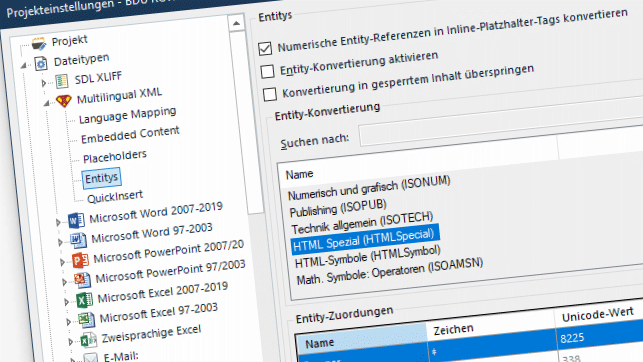
Wie man SDL/RWS Trados Studio dazu kriegt, mit WordPress WPMLs XLIFF-Dateien zusammenzuarbeiten.
Übersetzungsgerechtes Schreiben: Der Text
Worauf sollte man beim Verfassen von Texten achten, die übersetzt werden sollen? Rechtschreibung, Grammatik, Stil, Textstruktur uvm.
Übersetzungsgerechtes Schreiben: Wie senke ich Übersetzungskosten?
Erfahren Sie, was es mit „übersetzungsgerechtem Schreiben“ auf sich hat und wie es helfen kann, Mehrkosten bei der Übersetzung zu vermeiden.
Felder bestellen: Folgende Seitenzahl in MS Word
Dies ist mal wieder einer dieser Artikel, die mir helfen, nicht noch einmal so lang nach einer Lösung für ein an sich simples Problem suchen zu müssen: „Wie kann ich…